
팀플02. 데이터 웨어하우스를 이용한 대시보드 구성
: 무신사 스탠다드 상품 분석 대시보드
프로젝트 기간 : 2023년 12월 4일 (월) ~ 12월 8일 (금) 총 5일
실제 작업 기간 : 2023년 12월 1일 (토) ~ 12월 8일 (금)
(대략 38시간 정도 투자)
1. 프로젝트 소개
2. 프로젝트 진행 내용
3. 프로젝트 결과
4. 회고
프로젝트 소개
프로젝트 공지
2차 프로젝트의 주제는 "데이터 웨어하우스를 이용한 대시보드 구성" 이다. 본 프로젝트의 목표는 데이터 웨어하우스 구축 및 대시보드 활용을 통해 수집되는 데이터에 대한 관리와 시각화 방법에 대해 알아보며 데이터 엔지니어링 기술 역량 강화에 필요한 지식들을 쌓는 것이다. 구체적인 기술로는 Redshift, Superset 등을 사용한다.
프로젝트 주제 선정
- 공공데이터 포털 이용한 교통사고 분석
- 공공데이터 포털 이용한 해외 안전 분석
- https://asil.kr/asil/ 부동산 매매 거래 분석
- https://ourworldindata.org/ 환경 오염 분석
다양한 주제 후보가 있었지만, 최종적으로 선정된 것은 무신사 스탠다드 상품 분석 대시보드이다. 교통사고 분석은 데이터의 수가 적을 것 같았고, 부동산 매매는 데이터 크롤링이 어려워 보였다. 환경 오염 분석은 좋은 데이터가 많았지만 이미 그 데이터를 기반으로 시각화 자료가 많이 만들어져 있어서 단지 복사-붙여넣기를 하는 수준에 이르러 배우는 영역이 줄어들 것 같았다.
그래서 실제 기업 데이터팀 입장이 되어 현재 상품에 대한 인사이트를 얻기 위한 분석을 할 수 있는 무신사 스탠다드 상품 분석을 주제로 선정하였다.
프로젝트 파악
이번 프로젝트는 데이터를 가져와서 최종 분석 대시보드를 만드는 것이다. AWS를 이용해서 데이터 웨어하우스 처리를 하고, 시각화 툴로 대시보드를 만들면 된다.
- 데이터 수집 -> S3 저장소 -> Redshift (데이터 웨어하우스) or RDS (관계형 데이터베이스) -> Superset (대시보드)
데이터 수집은 캐글이나 공공데이터에서 가져올 것인지, 크롤링을 진행할 것인지 고민해봐야 한다. 만약 데이터셋을 바로 파일로 가져올수 있는 환경(ex. 캐글)이라면 csv 파일을 다운로드받아 DB / s3에 바로 적재해서 작업할수도 있고, 공공데이터와 같이 API를 호출해야한다면 API 결과를 s3가 아닌 DB에 바로 쌓는 방식을 선택할 수 있다. 하지만 소스가 제한적이다보니 프로젝트 방향과 꼭 맞는 데이터셋을 바로 찾기 힘들 수도 있다. 반면 크롤링은 그런 면에서 자유도가 높고 진입장벽이 비교적 낮다.
저장소가 반드시 s3여야하는건 아니지만, AWS 환경에서 비정형 데이터를 수집하는 레이크로 s3가 가장 적합하기 때문에 s3를 사용하도록 권장하고 있다.
비슷한 결로, 꼭 redshift에서 Transformation을 할 필요도 없다. redshift는 매우 비싼 서비스다. 일반적인 rds에서 처리 가능한 정도의 데이터 크기라면 rds에서 작업해도 무방할 것이다.
이처럼 현재 프로젝트의 ETL 파이프라인에서 더 최선의 방법(성능 / 비용)은 무엇일까? 를 생각하는 것이 중요하다.
프로젝트 진행 내용 (TIL)
맡은 역할 : 상품 상세 정보 및 고객 관련 데이터 크롤링, 테이블 모델링, 차트 생성 및 대시보드 구성, 노션에 프로젝트 정리하기
사전 미팅
토요일 오후 9시, 첫 미팅을 가졌다. 별 다른 소득은 없이 월요일 오전에 각자 생각해온 주제를 선정하기로 결정했다.
1일차
주제 선정 및 역할 분담
크롤링 진행 (1) 크롤러 제작
주제를 최종적으로 선정하고 역할을 분담했다. ETL 3, ELT 2로 나누었는데 역할을 나누기 애매했다. 나는 ETL을 담당하여 크롤링을 하고, 데이터 파이프라인을 구축하면 될 것 같다.
전체적인 할 일은 아래와 같이 생각해봤다.
| 분류 | 내용 |
| 세팅 | AWS 세팅 1) S3 : 저장소에 폴더 생성 후 csv 파일 저장 2) Redshift (혹은 rds) : - Redshift 클러스터 생성 - IAM 권한 생성 및 연결 (S3에 접근 권한 부여) - 깃허브 세팅 1) 레포 생성 후 계정 공유 2) 코드 업로드 (각 브랜치 사용) Superset 대시보드 세팅 1) Superset <-> DB (Redshift) 연결 |
| ETL | 데이터 크롤링 .csv 형태 데이터를 데이터 웨어하우스로 적재 - Redshift COPY 명령어로 S3의 csv 파일을 Redshift로 이동 |
| ELT | 데이터 가공 분석 테이블 생성 |
| 시각화 | 데이터셋 생성 차트 생성 대시보드 구성 |
그리고 크롤링 할 일은 다음과 같이 생각했다.
- 웹페이지 HTML 코드 확인 >> HTML 요소 추출 >> 크롤링 코드 작성 >> 반복 및 저장 >> 자동화 및 예외 처리 >> 데이터 정제 및 분석
3명이서 테이블을 나누어 크롤링 영역을 구분지었다. 나는 고객 반응 테이블을 만들기로 했다. 모바일 버전으로 크롤링할 예정이었는데, 모바일 주소를 찾기 못하였다.
- 상품 정보 : 품번, 상품명, 카테고리 (대분류, 중분류), 상품 가격
- 부가 정보 : 품번, 성별, 사이즈, (키, 몸무게)
- 고객 반응 : 품번, 구매후기 평점, 후기 수, 좋아요 수, 조회수, 누적판매, 구매성별 >> 맡은 파트
1) 웹페이지 HTML 코드 확인 및 요소 추출
| 분류 | 데이터 예시 | 요소 코드 | 최종 형태 |
| 품번 | MIPT0006-BK | p.product_article_contents > strong #text | product_id = MIPT0006-BK |
| 구매후기 평점 | 4.8 | span.prd-score__rating | score_rating = 4.8 |
| 후기 수 | 1. 후기 26,319개 보기 2. 26,319 |
1. span.prd-score__review-count 2. span#review_total |
review_cnt = 26319 |
| 좋아요 수 | 43,656 | span.prd_like_cnt | like_cnt = 43656 |
| 조회 수 | 5.5만회 이상 | p.product_article_contents strong#pageview_1m | view_1m = 55000 |
| 누적 판매 | 2.4만개 이상 | p.product_article_contents strong#sales_1y_qty |
sales_1y = 24000 |
| 구매 성별 | 남성 6% 여성 94% |
 dl.label_info > df.label_info_name |
sale_m = 6 sale_f = 94 |
- 상품 : section > ui brandshop-product brandshop-product--default-style > li brandshop-product__list
- 페이지 버튼 : div n-line-bottom > div n-list-paging > button paging gtm-catch-click (is-active)
2) 크롤링 코드 작성
# 1. 라이브러리 설치
!pip install beautifulsoup4
!pip install requests
!pip install selenium
# 2. 필요한 모듈과 라이브러리 로딩
import requests
from bs4 import BeautifulSoup
from selenium import webdriverfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import pandas as pd
import requests
# 총 페이지 구하기
response = requests.get("https://www.musinsa.com/brands/musinsastandard")
soup = BeautifulSoup(response.text, "html.parser")
total_page = soup.find('span', attrs={'class':'totalPagingNum'}).text
# 데이터를 담을 리스트 생성
data_list = []
# 전체 페이지 수(total_page)를 기반으로 페이지 순회
for p in int(total_page) :
page = p+1
page_url = f"https://www.musinsa.com/brands/musinsastandard?category3DepthCodes=&category2DepthCodes=&category1DepthCode=&colorCodes=&startPrice=&endPrice=&exclusiveYn=&includeSoldOut=&saleGoods=&timeSale=&includeKeywords=&sortCode=NEW&tags=&page={page}&size=90&listViewType=small&campaignCode=&groupSale=&outletGoods=&plusDelivery="
response = requests.get(page_url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# 각 상품의 상세 페이지에 접속하여 정보 크롤링하기
i = 0
while True :
print("action", page, "-", i/2, "품번 | 평점 | 후기 | 좋아요 | 조회수 | 누적 판매 | 구매성별")
# 상품 목록에서 각 상품의 링크 찾기
product_url = soup.find_all('a', attrs={'name':'goods_link'})[i]['href']
end = soup.find_all('a', attrs={'name':'goods_link'})[-1]['href']
i += 2
product_driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) # 크롬 드라이버 실행
product_driver.get("http:" + product_url)
product_driver.implicitly_wait(3)
product_page_source = product_driver.page_source
if '404 Not Found' not in product_page_source:
product_soup = BeautifulSoup(product_page_source, 'html.parser')
def get_text_or_null(selector):
try:
return product_soup.select(selector)[0].text
except (IndexError, ValueError):
return 'null'
product_id = get_text_or_null('div.product_info_section > ul.product_article > li > p.product_article_contents').split(' ')[-1].strip()
score_rating = get_text_or_null('span.prd-score__rating')
review_cnt = get_text_or_null('span#review_total')
like_cnt = get_text_or_null('span.prd_like_cnt')
view_1m = get_text_or_null('#pageview_1m')
sales_1y = get_text_or_null('#sales_1y_qty')
sale_m = get_text_or_null('.label_info_value')
if sale_m.lower() != 'null':
sale_f = str(100 - int(sale_m[:-1])) + "%"
else:
sale_f = 'null'
data = {
'product_id': product_id, 'score_rating': score_rating,
'review_cnt': review_cnt, 'like_cnt': like_cnt,
'view_1m': view_1m, 'sales_1y': sales_1y,
'sale_m': sale_m, 'sale_f': sale_f
}
data_list.append(data)
else:
print(f"상세 페이지에 접근하지 못했습니다. 상태 코드: {product_res.status_code}")
product_driver.quit()
if product_url == end : break
else:
print(f"목록 페이지에 접근하지 못했습니다. 상태 코드: {res.status_code}")
df = pd.DataFrame(data_list)
df.to_csv('product_reactions.csv', index=False)
2일차
크롤링 진행 (2) 데이터 크롤링 1차
크롤링 난관 :
- 기본적으로 낮은 사양, 오래 걸리는 시간, 계속 지켜보지 않으면 에러 발생
- VSC에서 멈춘 경우, print 내용을 긁어와서 정보 살리기
- CSV 파일 합치기
가져와야 하는 상품의 데이터 갯수는 총 5000개가 넘는다. 게다가 많은 정보를 가져와야 하기 때문에 + 컴퓨터 사양을 고려해보니 한 상품의 데이터를 가져오는 데에 약 10초의 시간이 걸린다. 한 페이지에 상품은 90개, 15분 정도. 최소 총 14시간이 소요되는 것이다.
코드가 오류날 때마다 조금씩 수정하면서 진행했다. 힘들었던 점은 크롤링을 돌려놓고 자리를 비우면 어느 순간 네트워크 연결이 끊겼다며 크롤링이 중단된다는 것이다. 화면만 켜놔서도 안 되고, 20-30분에 한 번씩 마우스라도 움직여주어야 했다. 끊길까봐 함부로 무언가를 건드리지도 못했다. (컴퓨터가 과부하되는 문제도 있었지만)
한 번은 컴퓨터가 멈춰서 재부팅을 해야 했는데, 코드 내에 잘 작동되고 있는지 작성한 print문 덕분에 데이터를 잃지 않을 수 있었다. 이 때 배운 점은 print의 중요성과, VSC에서 터미널을 돌리는 것보다 주피터랩에서 ipynb 파일로 처리하는 것이 더 낫다는 것이다. VSC에서 데이터 리스트에 넣어놓은 데이터들을 따로 불러낼 수 없었지만, 주피터랩은 cell이 나누어져 있어서 다시 불러낼 수 있었다. 그래서 중간에 크롤링이 멈추면 여태까지의 정보를 저장하고 그 이후 내용부터 다시 크롤링 할 수 있었다. VSC의 경우, 터미널에서 print된 내용을 긁어와서 따로 csv로 처리해주어야 했다.
print 내용 -> csv 파일 저장하는 코드
raw_data = """ print문 내용
print문 내용"""
data1 = raw_data.splitlines()
selected_lines = [data1[i] for i in range(len(data1)) if i % 2 != 0]
data_list = []
print(selected_lines[0:5])
print(type(selected_lines))
for d in selected_lines :
dd = d.split(' | ')
product_id, score_rating, review_cnt, like_cnt = dd[0], dd[1], dd[2], dd[3]
view_1m, sales_1y, sale_m, sale_f = dd[4], dd[5], dd[6], dd[7]
#product_url = dd[8]
data = {
'product_id': product_id, 'score_rating': score_rating,
'review_cnt': review_cnt, 'like_cnt': like_cnt,
'view_1m': view_1m, 'sales_1y': sales_1y,
'sale_m': sale_m, 'sale_f': sale_f,
#'url' : product_url
}
print(data)
data_list.append(data)
df = pd.DataFrame(data_list)
df.to_csv('product_reactions.csv', index=False)
나중에는 페이지를 나누어서 여러 개의 크롤러를 생성해 돌렸다. 속도가 무엇이 더 빠른 것인지는 모르겠다. 체감 상 비슷한 것 같기도 한데, 그래도 여러 개로 나누는 것이 더 빠르겠지 생각하기로 했다. 따라서, csv를 합치는 코드가 필요해졌다.
csv파일 여러 개를 하나로 합치는 코드
import pandas as pd
data1 = pd.read_csv('product_reactions1-30.csv')
data2 = pd.read_csv('product_reactions30-57.csv')
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
result = pd.concat([df1, df2], ignore_index=True)
result = result.drop_duplicates(subset='product_id')
result.to_csv('product_reactions.csv', index=False)
한 번에 여러 개를 합칠 수도 있지만, 일단 예시로 2개의 데이터 프레임만 작성하였다. merge보다는 concat이 나아서 이것으로 선택했고, 이는 중복을 제거하지 않으므로 별도로 drop_duplicates를 입력해서 중복을 처리해주었다. 모든 페이지 크롤링이 끝나면 합치면 될 것 같다.
3일차
크롤링 진행 (3) 크롤링 완료 및 데이터 정제
테이블 모델링
1. 크롤링
오늘의 문제점은 '아울렛 상품'의 경우 품목이 '상품'으로 된다는 점과, 오류때문인지 온통 'null'값인 상품 데이터가 존재한다는 점이다. 이를 해결하기 위해 csv 파일을 데이터 프레임으로 불러오고, 데이터 프레임 내용을 확인한 후 수정하는 작업을 거쳤다. 엑셀에서 해도 되겠지만 따로 엑셀 파일이 없어서 파이썬으로 진행했다.
csv 파일 내 데이터 수정하기
# 1. csv 파일 가져오기
data = pd.read_csv('product_reactions1-18.csv')
df = pd.DataFrame(data)
# 2. 데이터 확인하기
df[df['product_id'] == '상품']
df[df['product_id'] == 'null']
# 3-1. 데이터 수정하기
df.loc[19, 'product_id'] = "{상품코드}" # 19행의 product_id를 {상품코드}로 변경
# 3-2. 데이터 삭제하기
df = df.drop(df.index[-1])
# 4. 다시 csv 파일로 저장하기
df.to_csv('product_reactions1-18.csv', index=False)
이러한 과정을 거쳐서 드디어 거진 24시간 만에 크롤링을 완수했다. (사실 첫 날 저녁에 돌리고 자려고 했는데 에러 때문에 못 했던 것을 생각하면 더 오랜 기간을 크롤링을 위해 투자했다고 볼 수 있다.)
최종 csv 파일
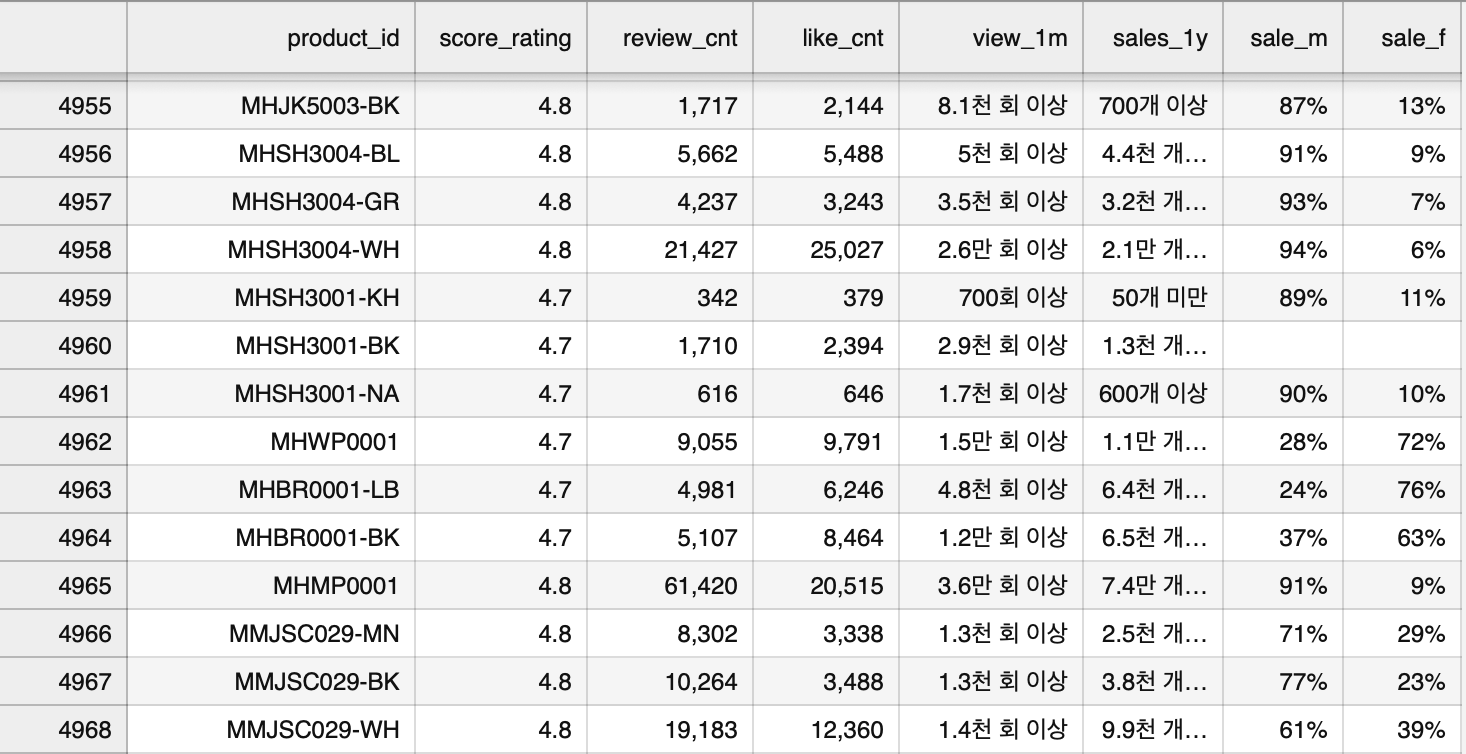
다른 팀원의 csv 파일 :


2. 테이블 모델링
데이터 분석을 위한 분석용 테이블을 만들어야 하는데, 이 테이블을 어떻게 만들면 좋을 지에 대하여 모델링을 진행했다. 대시보드에 어떤 시각화 자료가 있으면 좋을지 의견을 냈었는데, 개인 의견에 대한 테이블 모델링을 진행하여 분석용 테이블 제작하는 팀원에게 공유하기로 했다.
1) 전체 상품 수 : 모든 품목 나와있는 테이블 행 갯수
2) 1년 누적 판매액 : SUM(상품 가격 * 누적 판매 수)
3) 카테고리별 평균 가격
| 카테고리 - DISTINCT | 상품 가격 - AVG |
4) 가격대별 누적 판매 분석
필요 필드 (크롤링) : 상품 가격, 누적 판매 수
데이터 가공 : 상품 가격에 따라 가격대 분류 필드 추가, 누적 판매액 계산한 필드 추가 (상품 가격 * 누적 판매의 총합)
| 가격대 분류 | 누적 판매액 - SUM(상품 가격 * 누적 판매) | 상품 가격 | 누적 판매 수 |
| 5만원 이하 | 총합 | null | null |
| 5만원 이하 | null | ||
| 5만원 ~ 10만원 | 총합 | null | null |
| 5만원 ~ 10만원 | null | ||
| 10만원 ~ 20만원 | 총합 | null | null |
| 10만원 ~ 20만원 | null | ||
| 20만원 ~ 30만원 | 총합 | null | null |
| 20만원 ~ 30만원 | null | ||
| 30만원 이상 | 총합 | null | null |
| 30만원 이상 | null |
4일차
AWS 세팅 확인
Superset 대시보드 확인
분석 테이블을 공유받았다. 이를 바탕으로 이제 Superset에서 대시보드를 생성하면 되는데, 그 전에 먼저 AWS 세팅을 하는 방법과 연결까지의 과정을 살펴보고자 한다.
1. AWS 세팅
아래의 과정은 같은 팀원이 작성한 내용을 바탕으로 추가하였다.
1) AWS S3 버킷 생성

2) AWS IAM에서 Redshift와 S3에 FullAccess 권한을 포함하는 역할 생성


3) AWS Redshift에 해당 IAM을 연결하여 클러스터 생성


4) 팀원들이 S3 버킷에 직접 액세스해서 파일을 업로드 할 수 있도록 IAM에서 권한을 가진 사용자 생성 (사용은 보류)
팀원이 AWS 콘솔을 통해 S3 버킷에 파일을 업로드 할 수 있게 하려면 사용자 생성 시 AWS Identity Center 활성화가 필요한데, 이는 Redshift의 free trial 등과는 관계 없이 과금이 된다고 하여 콘솔 액세스를 비활성화 해야 했다.
웹 콘솔 방식 대신 프로그래밍 방식으로 액세스할 수 있는데, 이 경우 팀원이 AWS SDK나 CLI를 설치해야 한다.
[ SDK 설치법 : Python - Boto3 SDK (AWS SDK for Python): pip install boto3 ]
복잡한 것은 아니지만, S3 버킷 소유주가 직접 올리는 것이 간단하여 이렇게 진행하기로 하였다.


5) S3 버킷에 크롤링한 데이터 업로드


6) 분석 테이블 생성 후 S3에 업로드
💡 팀원이 진행한 방식 대신에, Redshift 데이터 웨어하우스 자체에서 분석 테이블을 생성할 수 있지 않을까? 생각을 해보았다.
구글 Colab을 이용했다.
https://colab.research.google.com/drive/19sMdhnfIrswZ-Wz93ooJjIsEsruyi-YH#scrollTo=jzxDtIkEUN4F
Devcourse team6 Musinsa Standard Redshift
Colaboratory notebook
colab.research.google.com
!pip install pandas pandasql
import pandas as pd
import pandasql as psql
#중요
!pip install ipython-sql==0.4.1
!pip install SQLAlchemy==1.4.49
from google.colab import drive
drive.mount('/content/drive')
# raw_data로부터 product_info.csv 읽기
info = pd.read_csv('drive/My Drive/Musinsa Standard DashBoard/raw_data/product_info.csv')
# raw_data로부터 product_reactions_1.csv 읽기
reaction= pd.read_csv('drive/My Drive/Musinsa Standard DashBoard/raw_data/product_reactions_1.csv')
query = """
SELECT *
FROM info
INNER JOIN reaction
ON info.product_id = reaction.product_id
"""
product = psql.sqldf(query, locals())
...
main = psql.sqldf(query, locals())
main.to_csv('Comparative_Information_by_Main_Category.csv', index=False)
7) Redshift 테이블 스키마 정하기 (raw_data, analytics)
8) Query 실행을 위해 Google Colab으로 Redshift 연결 → 나중에 그냥 Redshift 쿼리 편집기로 변경
- 클러스터(작업그룹)에서 퍼블릭 액세스 허용으로 설정 변경
- VPC security group의 인바운드 룰 추가(하려고 했는데 이미 있던 가장 위쪽의 규칙이 이미 같은 역할을 하고 있는듯 했다)


Redshift 접속정보 : 엔드포인트, 관리자 ID, 관리자 Password, IAM 리소스 정보 (이미 닫아놓아서 현재는 사용 불가능하다.)
- 엔드포인트 : devcourse-de2-team6.059583123016.ap-northeast-2.redshift-serverless.amazonaws.com:5439/dev
- 관리자 ID : admin
- 관리자 Password : Admin1234
- IAM 리소스 정보 : arn aws iam::059583123016:role/Redshift-S3-FullAccessRole
9) S3 버킷으로부터 Redshift에 COPY




2. Superset 설정
1) Docker로 Superset 실행 후 admin으로 로그인



5일차
대시보드 생성
Superset을 설치하여 이용하는 방법은 총 3가지가 있다.
- Preset.io 셋업 - Starter 무료 플랜이 있지만, 회사 메일이 있는 경우만 사용 가능 (Superset 오픈소스 기반 변경된 버전)
- Docker를 통한 셋업 - Docker에 익숙하고 개인 컴퓨터 사양이 충분히 좋다면 Docker 이용이 더 좋음
- 리눅스 서버에 설치하는 방법
Docker를 통해서 셋업하는 것이 좋겠지만, 일단은 컴퓨터 사양이 좋은 편이 아니라서 Preset을 통해서 테스트를 해볼 예정이다. Preset에는 회사용 이메일 계정이 필요하다. 무료 플랜은 계속 사용할 수 있지만, 14일간은 프리미엄 기능을 사용할 수 있어서 아쉽긴 했다. (이번 프로젝트를 위해 하루만 사용하다 말 예정이었으니까)
필요한 대시보드 차트 파악하기
➀ 전체 제품 수, 1년 누적 판매액, 조회수 대비 누적 판매 수 (월, 연으로 날짜 기준이 안 맞음)
+ 월간 전체 조회수, 연간 누적 판매수
➁ 카테고리별 총 매출, 평균 가격
➂ 카테고리별 만족도 평가 (평균 조회수, 평균 누적 구매 수, 평균 좋아요)
➃ 가격대별 상품 수, 누적 구매 수, 누적 판매액
분석용 테이블 파악하기
➀ Price information : price range (가격대), product count (상품 수), annual_units_sold (누적 구매 수), annual_sales (누적 판매액), sales_per_product (제품당 매출)
➁ Overall information : 건수, 연간 총 매출, 월간 전체 조회수, 연간 누적 판매수, 조회수 대비 실 판매 비율, 남성/여성 구매자 비율 평균
➂ Comparative information (Main category) : 대분류, 평균 가격, 연간 총 매출, 월간 평균 조회수, 연간 평균 판매수, 조회수 대비 판매수, 남성/여성 구매자 비율 평균
➃ Comparative information (Sub category) : 중분류, 평균 좋아요, 평균 평점, 평균 가격, 연간 총 매출, 월간 평균 조회수, 연간 평균 판매수, 조회수 대비 판매수, 남성/여성 구매자 비율 평균
→ 주제에 맞게 SUM, AVG 등등을 전부 처리해서 그 결과값만 분석 테이블에 저장해두어서 차트로 만들기에 자유로움이 부족했다.
Superset 대시보드 생성하기
1) Database 연결
2) Dataset 생성
3) Chart 제작
⚠️ 차트가 제대로 저장되지 않아서 날라가는 경우가 빈번하게 발생한다. 꼭 저장되었다고 해도 다시 한 번 확인해야 할 것 같다.
4) Dash board 연결 및 제작

이 정도 제작을 했는데, 생각보다 데이터가 마땅치 않아서 그래프가 예쁘지 않고 무의미한 것들이 많아 보였다. 생각보다 지표가 많이 나오지 않아서 쓸 수 있는 것이 없었다. preset.io에서 제공하는 예시 대시보드만 보아도 한 페이지로 끝나지 않는데, 우리의 결과물은 굉장히 단조로웠다.
+
다른 팀원의 컴퓨터에서 최종 대시보드를 만들었다. 화면 공유를 하여 같이 구성했다.

프로젝트 결과
프로젝트 개요
무신사 스탠다드 상품 분석 대시보드
실제 기업의 데이터 팀이 되어 MD에게 현재 상품 상황에 대한 분석 대시보드를 제공한다고 가정하여 프로젝트를 시작했다. 무신사 스탠다드 상품 정보를 크롤링한 데이터를 기반으로 집계된 상품 갯수와 총 매출액이 얼마인지 보여주고, 그 외에도 카테고리별 상품 비율과 기타 정보, 가격대별 상품 갯수, 성별 사이즈 선택 기준, 구매자 성별 비율 등 다양한 정보를 시각화된 그래프로 보여준다. 상황에 맞는 여러 그래프를 활용하여 단조롭지 않고 한 눈에 분석하기 편한 대시보드를 제작하고자 했다.
프로젝트 결과물
1) 깃 허브
https://github.com/proj2-6-1/scraping
2) 프로젝트 진행 관련 보고서
https://www.notion.so/6-1-b5aa242d09b14358835565294f852486
3) 프로젝트 결과물 소개 PPT
4) 프로젝트 시연 영상
5) 프로젝트 결과 발표
피드백
프로젝트 진행
- 프로젝트에서 어떤 고민을 했는가가 중요하다.
- 데이터의 종류가 많고 크기가 커질 때 어떻게 수행할 것인가가 중요하다.
- 현재는 데이터 크기가 작아서 간단할 수 있지만, 회사에서 데이터가 커지거나 종류가 다양해지면 문제가 생긴다. 이 경우 고민의 시간이 길 것이다
- 이 프로젝트에서 대시보드를 얼마나 예쁘게 보이게 하느냐가 중요한 것이 아니라, 예를 들어 연간 매출액 같은 스칼라 데이터를 보여주는 것보다 추이를 보여주는 것이 더 좋을 것 같다. (더 난이도가 있고, 프로젝트가 디벨롭 될 것이다.)
- 데이터를 어떻게 보여줄 것인가를 생각하면서 데이터를 어떻게 저장하고, 데이터 마트를 어떻게 구현할 것인가를 깊게 생각해볼 수 있다.
- 데이터 저장 측면에서 csv는 적절하지 않다 >> 왜 csv로 했는가?
- redshift가 비싸다면 다른 대안을 찾아보자
- CREATE, ALTER 등 DDL 같은 경우에는 한 명이 권한을 가지고 관리하는 것이 좋다
데이터 크롤링
- 크롤링을 동기, 비동기로 하느냐에 따라서 다를 것이다 (파이썬은 비동기 호출이 편한 언어)
- 크롤링 규모가 커지면 스크립트 구현 방식이 아니라 백엔드 API 이용해야 한다. 이 때 비동기 방식 사용한다.
데이터 처리
- 데이터 처리는 분산 처리가 트렌드이다. Redshift, BigQuery, Snowflake 등 도 분산 처리 프레임워크이다.
- 큰 데이터를 어떻게 처리하는지 "분산 처리"에 대해 추가적으로 공부하면 좋을 것 같다.
- Pandas는 데이터 분석에 초점이 맞추어져 있고, 분산 처리를 하기에 좋지는 않다. Pandas로 분석 처리 하기에 크다면 Spark를 이용하게 될 것이다.
- 데이터 프레임 단위로 다룬다는 공통점이 있지만, Pandas와 Spark의 차이점은?
- EMR이라는 Spark를 편하게 써볼 수 있는 AWS 서비스를 사용해보는 것도 추천한다.
- 데이터 처리 관련하여 한국어 강의가 별로 없으니, Udemy에서 영어 강의를 보는 것을 추천한다.
회고
이번 프로젝트의 결과물은 무척 아쉽다. 그래서 그런지 배우고 느낀 점이 굉장히 많다. 지난 프로젝트에서는 하나의 프로세스에 따라 잘 수행해 나가면서 배움을 느꼈다면, 이번 프로젝트에서는 실패를 통해 이러면 안 되는구나와 이렇게 했어야하는구나 등의 깨달음을 느꼈다.
처음에 막연하게 주제를 생각할 때는 한 판으로 보이는 대시보드를 만들면 되겠다는 섣부른 판단에 갇혀서 단순하게 생각했다. 근데 막상 해보니 데이터가 생각과는 다르다는 것을 느꼈다. 의미 있을 거라고 생각했던 분석 지표가 의미 없게 나와서 사용하기에 고민되는 경우도 있었고, 추가적으로 탭을 나누어 더 상세한 분석을 하려고 하여도 데이터가 부족하거나 분석용 테이블이 마땅치 않아서 진행하기 어려운 경우도 있었다. 기간이 넉넉했다면 시간을 더 투자해서 디벨롭 했겠지만, 한정적인 시간에서 진행을 하다보니까 한 번 틀어지니 다시 바로 잡기가 어려웠다.
만족스러운 결과물은 아니지만 그래도 배운 점은 많았기 때문에 좋은 경험이었다고 생각했다.
- 무엇이든 기획이 중요하다. 특히 WHY에 대한 설명을 할 수 있어야 한다.
- 마땅한 분석을 위해서는 현재 실력의 데이터 크롤링은 부족할 수 있다. 충분한 분석을 통해 인사이트를 얻을 만한 지표를 얻으려면 정말 많은 데이터가 필요한 것 같다.
- 분석용 테이블을 어떻게 구성하는 것이 좋을지 생각해보게 된다. 대시보드 툴에서 SQL을 이용하여 분석을 수행할 수 있기 때문에 미리 분석용 테이블에서 모든 것을 수행할 필요는 없었다. 대시보드 툴마다 다를 수도 있겠지만, 프로젝트 수행에 앞서 어떤 툴을 사용할 것이고 그 툴이 어떤 기능을 제공하는지, 그래서 어떻게 이용하면 되는지 고민과 기본적인 조사/숙지가 필요할 것 같다.
이번에는 그냥 무작정 배웠던 것을 따라해보자~ 라는 마인드가 통하지 않았던 것 같다. 첫 프로젝트는 이러한 마인드로도 충분했지만 (그 툴을 익히는 목적이었기 때문에), 이번에는 예시로 말했던 툴들이 너무나도 많았고, 어떤 것을 선택할 것인지 부터를 생각했어야 하는 것 같다. 사실 이 모든 것을 고민하고 (+시행착오) 완성까지 하기엔 교육생의 입장으로 5일은 짧은 것 같지만 어떻게든 되겠지! 싶다. 추후 시간을 더 들여서 완성하면 되니까.
'Data Engineering > grepp 데브코스 : 프로젝트' 카테고리의 다른 글
| 최종 팀플 (1) 주제 선정 및 고도화 (2) | 2024.03.04 |
|---|---|
| 최종 팀플 (0) 사전 준비 : 팀 빌딩, 협업 준비, 프로젝트 세팅 (3) | 2024.03.04 |
| (참고) 프로젝트 당부 사항 (0) | 2024.03.04 |
| [12주차_팀플03] End-to-end 데이터 파이프라인 구성하기 (0) | 2024.02.14 |
| [4주차_팀플01] 크롤한 웹데이터로 만들어보는 시각화 웹 서비스 (1) | 2023.11.11 |